roboflow활용해서 데이터셋 구축하고, 추후 커스텀 annotation tool을 활용해서 학습하는 방법을 알아보겠다.
왜냐면, roboflow는 1000장까지밖에 무료로 데이터셋을 제공하기 때문.
기존에 yolo 시리즈 데이터셋을 제작하는 annotation툴이 있다면 그대로 사용해도 무관하다.
목차
1. 데이터셋 만들기
2. 기본환경설치
3. 트레이닝
4. 테스트

1. 데이터셋 만들기(https://roboflow.ai/)
ROBOFLOW 접속 - 회원가입 - create project - Project Name(프로젝트이름), Type(오브젝트디텍션), Annotation Group(클래스이름 입력)

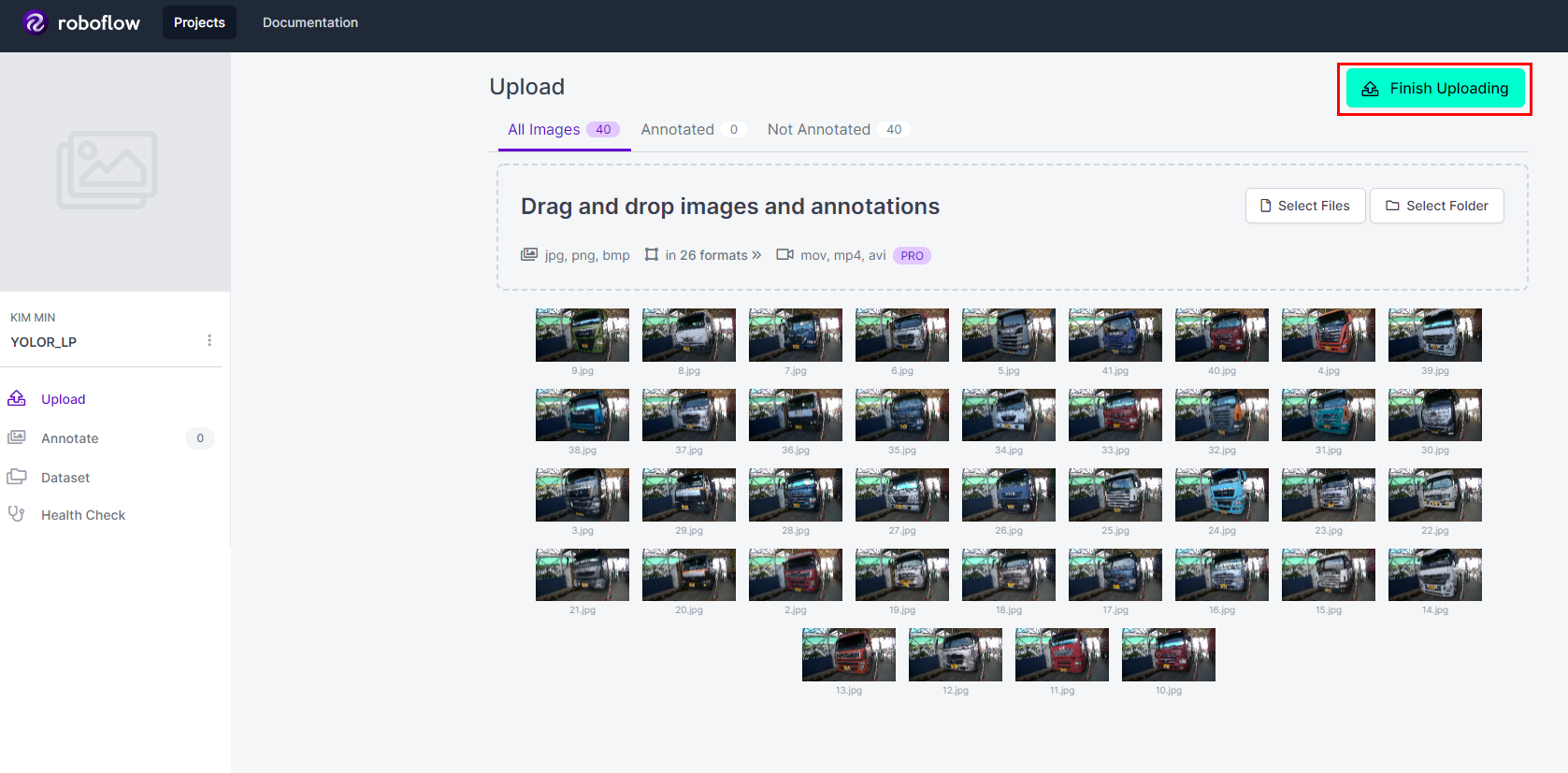
라벨링 할 이미지를 드래그앤드랍으로 가져온다음 Finish Uploading 버튼 클릭.(이미지를 모두 업로드한 뒤 실행할것)

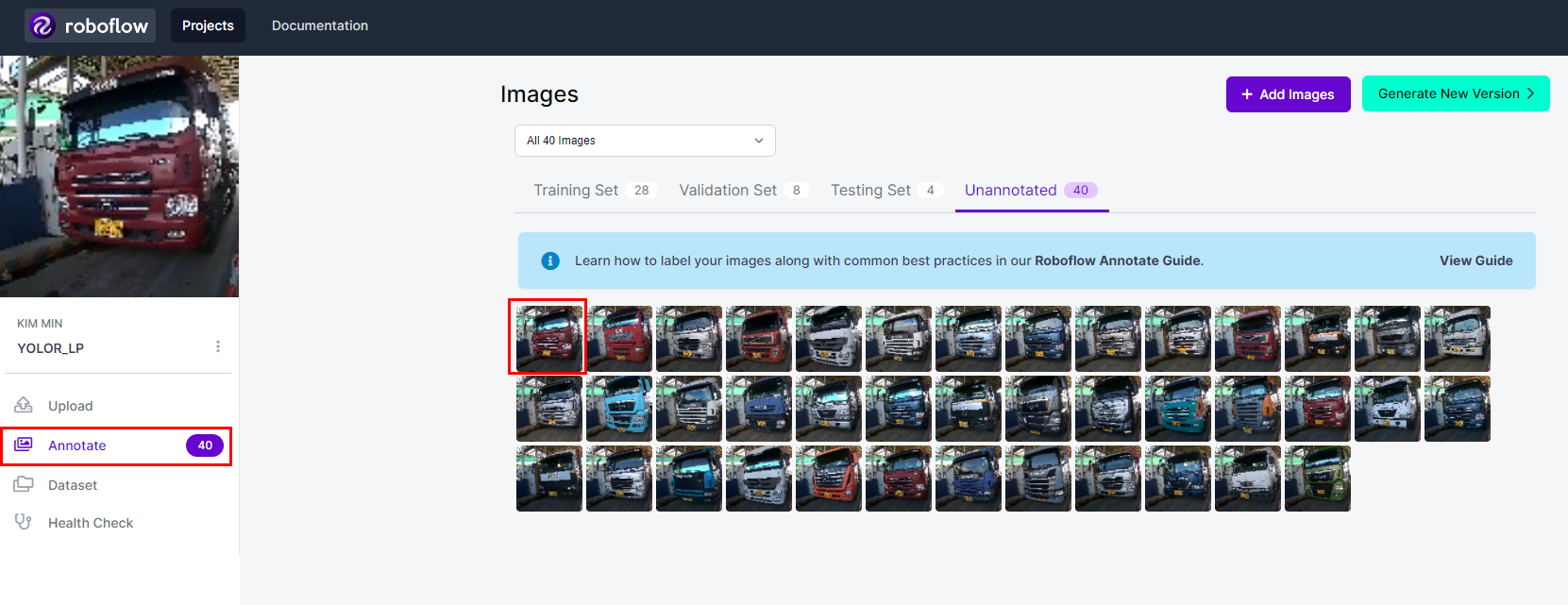
데이터셋을 나눌지 말지를 선택하는 단계가 나온다.(모두 트레인셋으로 사용할 수 있음)

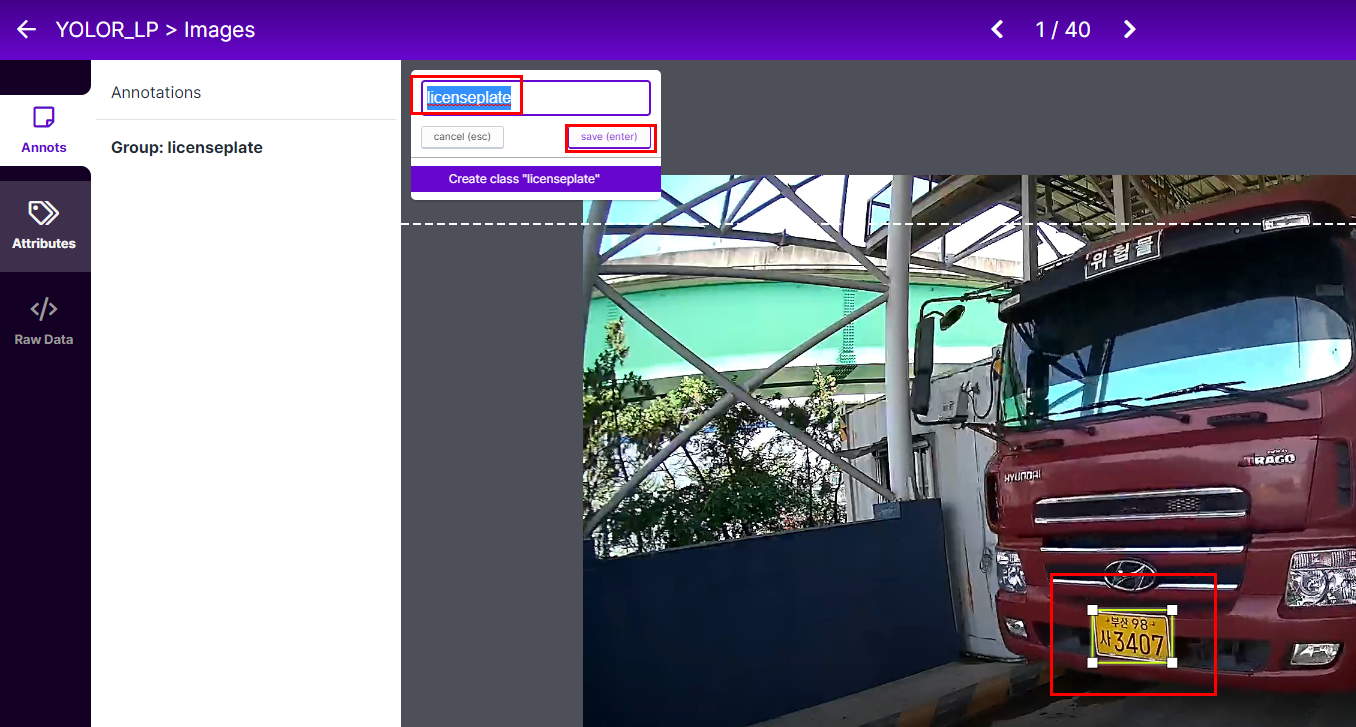
디텍션 할 부분을 바운딩박스 처리 해주면 좌측 상단 처럼 클래스를 입력하게 되어있음.
licenseplate로 클래스를 입력 - save 버튼 클릭 - 상단에 >버튼 눌러 다음으로 이동.
※ 만약 클래스가 2개 이상일 경우에는 동일하게 바운딩박스처리 하고 클래스명 입력해주면 됨.
모두 끝나면 뒤로가기 버튼 클릭

Train, Val, Test set이 잘 나눠진 것을 볼 수 있다.
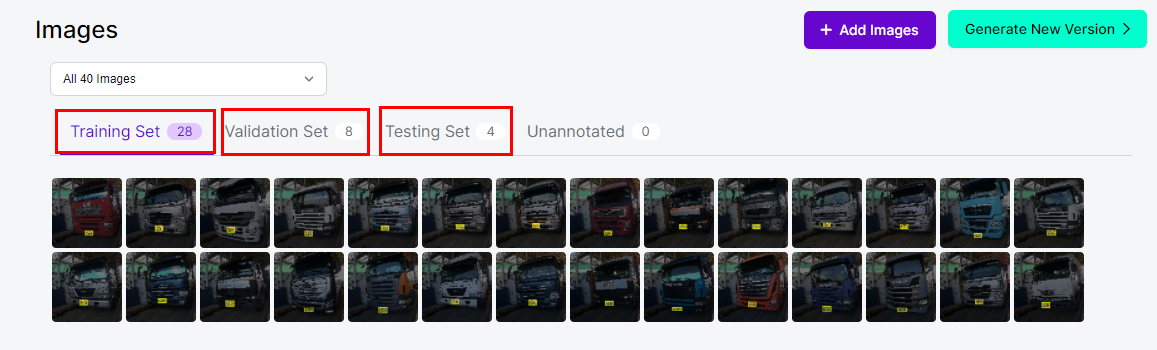
왼쪽 Dataset 클릭하면 우측과 같이 Preprocessing 기능을 추가할 수 있다.
Add Preprocessing Step 클릭 - 무료로 제공되는 Grayscale, Auto-Adjust Contrast를 사용해보겠다.


Grayscale 클릭 - Apply
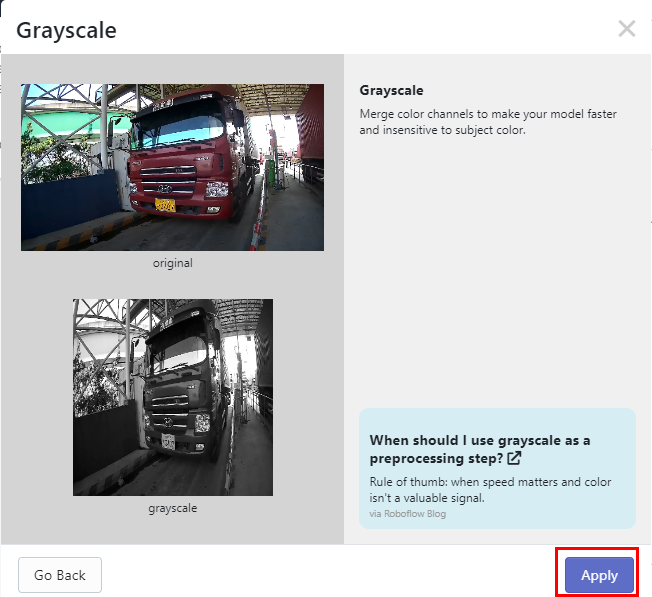
Apply 된 기능들을 확인한 다음 Continue 클릭
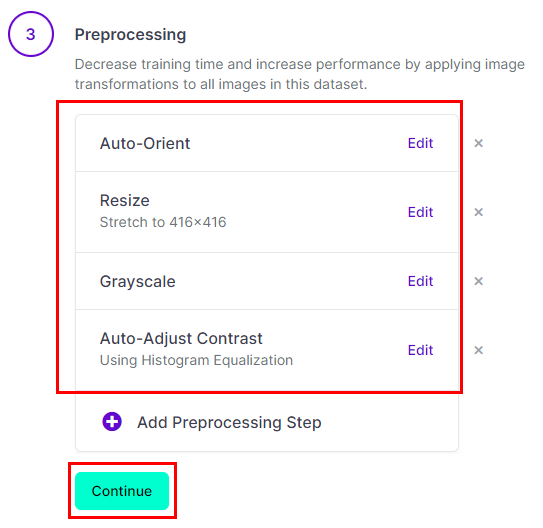
다음 Augmentation 기능을 추가한다. 원하는 기능을 눌러주고 Continue 클릭.


Generate!
무료버전에서는 3배까지 데이터셋을 증강시키는 기능을 제공한다.

날짜/시간/이름을 입력해주고 Save Name 클릭 - Export - YOLOv5 Pytorch - Continue 클릭
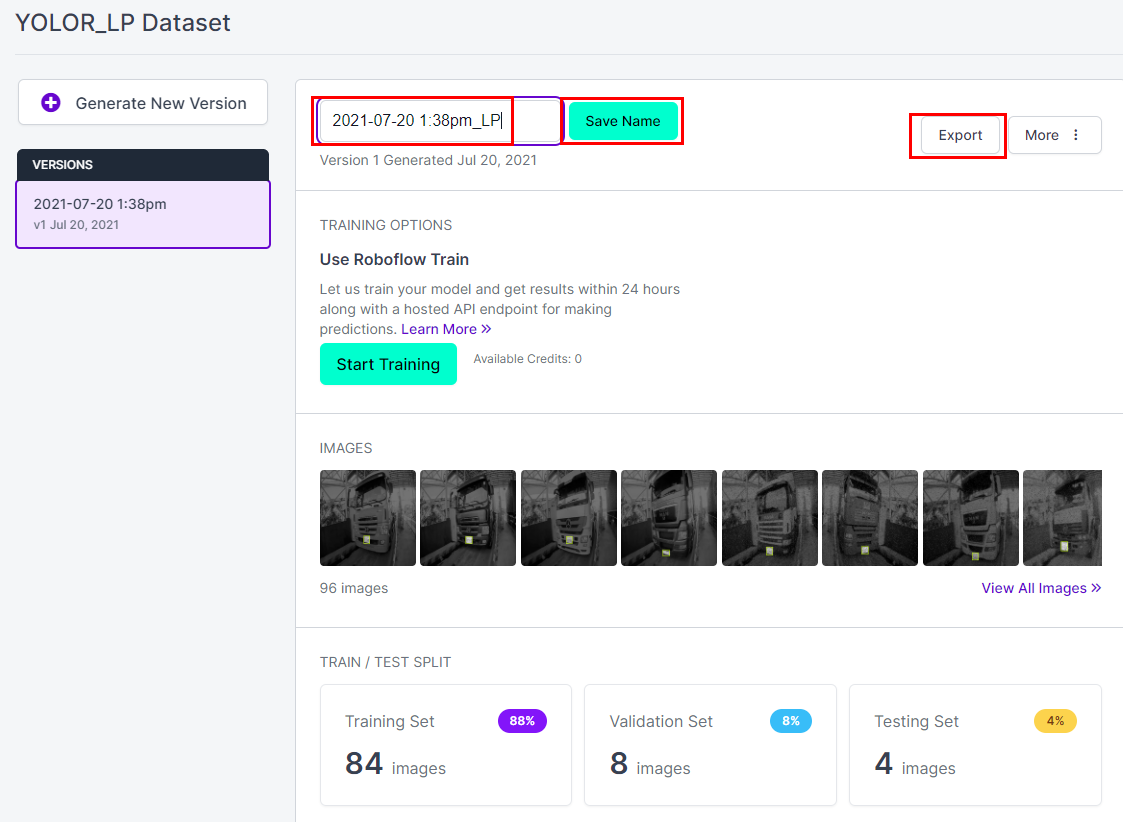

왼쪽 하단에 다운로드되는 것을 확인할 수 있다.


데이터셋 제작하는 방법 끝!
다음은 대망의 Custom Training 방법 포스팅! 아래 클릭
↓↓↓↓↓↓
https://hansonminlearning.tistory.com/72
YOLOR custom tutorial (YOLOR 커스텀 데이터셋 학습) - 2편(Train)
설치(Installation) # 원하는 디렉토리로 이동해서 YOLOR git clone! git clone https://github.com/roboflow-ai/yolor cd yolor git reset --hard eb3ef0b7472413d6740f5cde39beb1a2f5b8b5d1 # Requirement 설치..
hansonminlearning.tistory.com
'VAS > Centos 7 개발환경 구축' 카테고리의 다른 글
| CentOS 7 dev environment setting (0) | 2021.08.09 |
|---|---|
| Linux Centos 7, Ubuntu 우분투 USB 재설치 방법(윈도우10도 동일) (0) | 2021.08.09 |
| YOLOR custom tutorial (YOLOR 커스텀 데이터셋 학습) - 2편(Train) (2) | 2021.07.20 |
| git clone 할때 특정 branch clone하는 방법 (0) | 2021.06.23 |
| Human Pose Estimation 설치 및 좌표추출방법 (0) | 2021.04.13 |


댓글